AntV/AVA框架浅析-增强分析一些痛点
Stephen Cui ... 2022-05-04 09:00:00 About 8 min
Version: 2.0
Last Update: 2022-05-07
# 阿里可视化框架 AVA 系列文章
- [x] AntV/AVA 框架浅析-增强分析一些痛点
- [x] AntV/AVA Chart Linter 分析-图表检测与优化
- [ ] AntV/AVA ChartWizard 分析
- [ ] AntV/AVA ChartAdvisor 分析
- [ ] AntV/AVA LiteInsight 分析
# 一、什么是增强分析及其特点
首先我们来了解下什么是增强分析(Augmented),著名咨询公司(造词小能手) Gartner 给出了这样的定义:“增强分析是指使用机器学习和人工智能等提升能力的技术来协助进行数据准备、见解生成和见解解释,从而增强人们在分析和在商业分析平台中探索和分析数据的能力。”[1]。
这里我的理解是强调了使用机器学习和人工智能等技术作为手段辅助,来简化数据准备,挖掘数据中潜在的现象和规律,一般通过图形的方式解释自动挖掘的现象,其中人工智能的作用更多的是将沉淀于资深领域专家内在的规律以某种机器可理解的方式表达(例如算法以及机器学习模型)、代替人力进行繁琐的分析操作和沉淀跨行业、跨领域的业务知识,最终让"人人都是数据分析师"这一商业口号得以实现。
对比传统的数据可视化分析的软件,增强分析有着更为突出的优势[2]:
- 敏捷性:这里强调的是通过机器学习等手段,给出分析路径、缩小分析范围、建议分析模式以达到更快的数据反馈,减少不必要的操作。而目前一般的商业分析软件产品在这一点上仅仅停留在丰富用户体验,被动的辅助用户操作等方式上。
- 准确性:通过给机器制定检查规则就可以避免人为主观因素导致的误判,在一定程度上会有所提升。
- 效率:通过任务自动化来减少人们在处理数据时需要付出的精力和时间,例如数据抽取工具等。
- 信心:可以对增强技术进行定制,使其根据上下文显示数据和进行数据建模,从而让您能够确认直觉并对结论的质量充满信心。业务用户可能无法深入地了解分析技术,但他们确实了解自己所在的领域或行业,并且可以在评估如何使用增强分析提供的结果时应用这些专业知识。
# 二、AVA 技术框架
AVA 是为了更简便的可视分析而生的技术框架。 VA 代表可视分析(Visual Analytics),而第一个 A 具有多重涵义:其目标是成为一个自动化(Automated)、智能驱动(AI driven)、支持增强分析(Augmented)的可视分析解决方案。
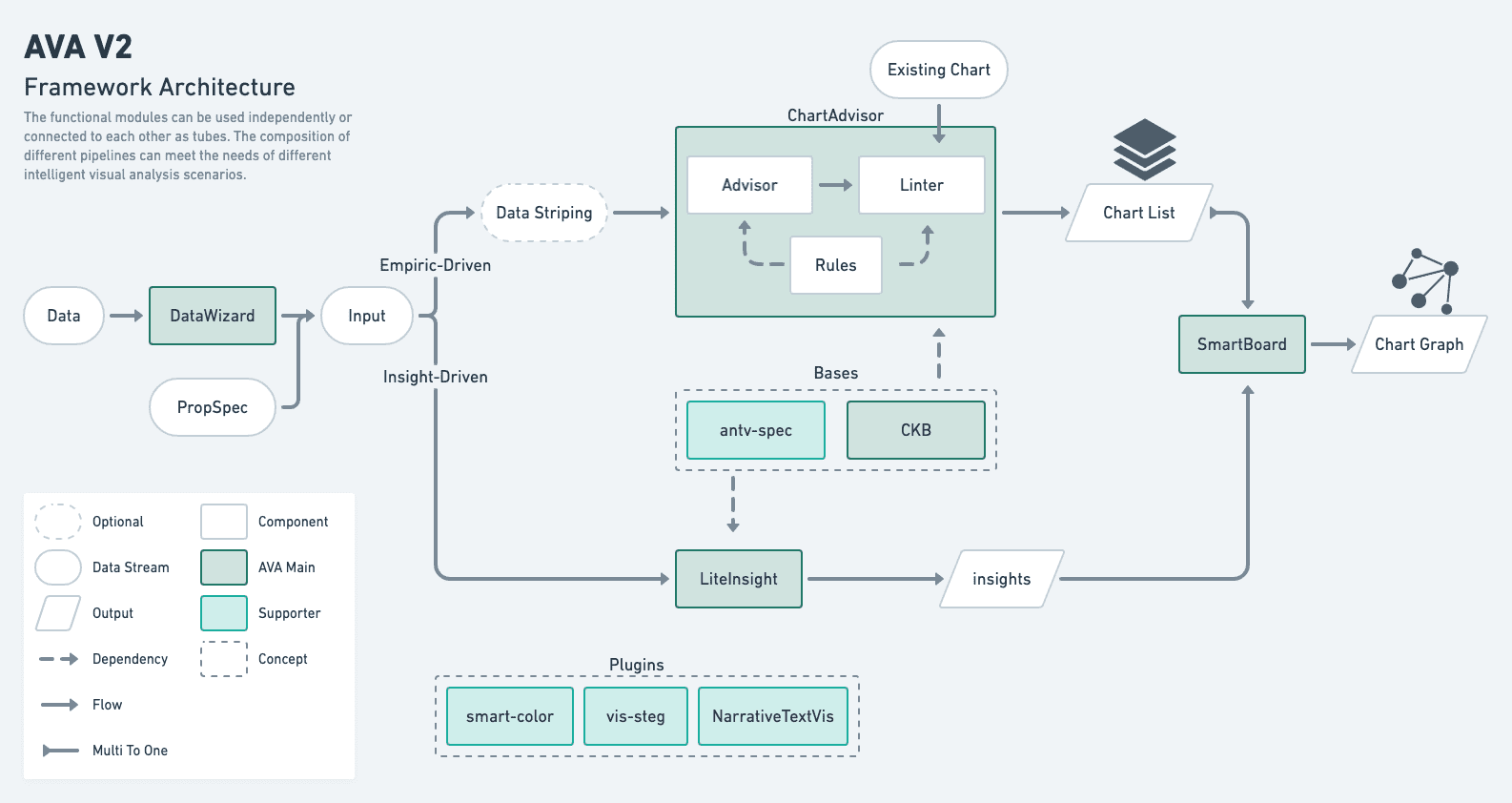
AVA 从数据的导入,数据检查,产生洞察(包含经验驱动和数据驱动两条推荐路径[3]),最终形成推荐图表的一个整体化解决方案,从使用者的角度而言,这其中给我印象最深刻的还是 AVA 的开放性、严谨性和易用性。
- 开放性:体现在对数据处理的每个环节都可以定制不同需求的参数和规则,支持全推荐链路的完整自定义能力[3:1]。同时,
AVA的代码也是面向开源社区的,对开源贡献也比较友好(例如补足代码规范和测试规范的提交请求会被很快合并)。 - 严谨性:体现在 Chart Knowledge Base 图表经验知识库的结构化定义上,同时规范了图表的名称和功能的对应关系,以及图表特性的维度定义。
- 易用性:体现在官方的文档和样例均可以容易的在现有的代码中集成,上手文档也描述的比较清晰。
接下来,从狭义的技术视角尝试分别说明。
# 1) 图表名称规范化
可谓无规矩不成方圆,如果对同样一个事物没有一个“统一”的标准就会导致技术实现的偏差和沟通的困难以及潜在的误解,官方则给出了更详细的解释[4],这是软件合作中重中之重,而往往被忽略的部分。前者有经典书籍<<The Grammar of Graphics>>[5]给出的图形学定义,而对于可视化图表领域同样需要一个统一且清晰的规范---Chart Knowledge Base(CKB),一个基于 JSON 形式的提供图表经验的知识库。
一个典型的折线图结构化定义如下:

对图表的分类来说,图表坐标系coord、图表类别category以及数据条件dataPres等因素是图表分类的主要因素,这里不展开说明。对于使用者来说,AVA 也完全支持图表自定义。
# 2) 自动提取数据特征
AVA 通过 DataWizard 模块对输入数据依据数据模式规则进行特征提取,生成字段特征(字段名称、数据类型、统计信息等),性质(连续性、离散性等),以及多字段间的关系(相关性、周期性等)[6],最后将提取的特征交给规则引擎生成图表。这一步数据提取意义可以说是在技术角度解决了人为基于经验的数据标记分类可能产生的错误,降低人工标记成本并提升效率。
举例来说,如果某一数据库视图中的数据列是整型类型,而在存储上以字符串的方式存储的数据库中,对于 BI 产品来讲数字类型往往是连续并可以产生聚合结果,起到统计汇总的提示,而如果以字符串的方式往往只能作为离散数据参与到图表的绘制中,一般需要人工介入修正/重新标记数据类型,这也是目前一些 BI 产品过渡依赖人工参与所产生的低效率问题。

# 3) 规则推荐/洞察推荐(Chart Advisor/Lite Insight)
为了更好的理解,这里主要介绍基于规则引擎的图表推荐,关于 LiteInsight 描述可以参考腾讯文章[7]。
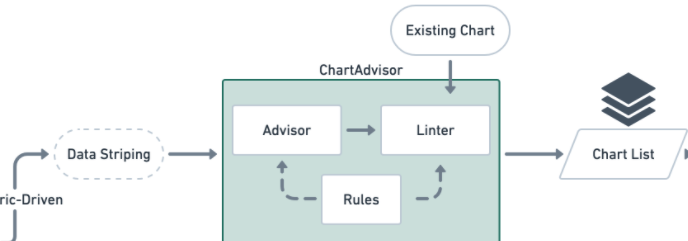
规则推荐基于从DataWizard抽取到的数据特征,以及基于图表业务场景的一系列权重规则Rules,最终得出推荐图表集合并按照得分大小排序 Chart List。AVA 支持扩展推表规则以及定义规则权重,这一点非常适合特定领域的更差异化的图表推荐实现。
# 4) 推荐规则约束 Lint(Chart Lint)
很多数据产品中有大量用户创建的存量图表。这些现有的可视化图表可能存在很多问题,视觉编码选择不当、缺少 legend、使用错误的 annotation 等问题都会阻碍我们从可视化中获取有效知识,甚至会使理解真实数据变得困难。想要尽力避免可视化中可能出现的错误,往往需要图表制作者自身具有良好的可视化专业设计和技术知识[3:2]。
核心作用在于基于规则自动识别错误和给出错误提示,提高图表推荐的准确性,并在 IEEE 会议上发表了一篇论文[8]。
在未来,我们期待看到的是,ChartLinter 能够成为图表不可或缺的一项能力。除了图表优化本身,我们已经发现 ChartLinter 还可以成为非侵入式的新手引导,告知我们的用户一些对 ta 有用的新功能。[9]
# 三、结语
本文以
增强分析为切入点,引出 AVA 作为一个增强分析的框架所解决的痛点和技术方案,但没有深入解析,其中涉及到一些算法和论文,需要花更多的时间仔细研究。
这篇文章的主要目的还是为了希望能抛砖引玉式的探讨商业 BI 产品在智能化方向上所面临的问题和现有的解决方案,欢迎留言讨论或者私信。